
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- c#
- C++
- HTML
- vim
- Flutter
- C# delegate
- git
- 플러터
- 유니티
- Algorithm
- 구조체
- c언어
- C언어 포인터
- dart 언어
- 도커
- c# 윈폼
- 포인터
- Unity
- Python
- c# winform
- gitlab
- jupyter
- Houdini
- c# 추상 클래스
- github
- 깃
- Data Structure
- 다트 언어
- docker
- jupyter lab
- Today
- Total
nomad-programmer
[Programming/Windows] 프로세스와 스레드 본문
프로그램은 하드디스크에 저장된 실행 파일을 말한다.
프로세스는 프로그램을 실행한 상태 즉, 하드디스크에서 메인 메모리로 코드와 데이터를 가져와 현 재 실행되고 있는 상태를 말한다. 프로세스는 동시에 여러 개가 존재할 수 있다.
프로세스 상태
오늘날의 운영체제는 대부분 멀티프로세스 기반이다. 프로세스 여러 개를 동시에 실행할 수 있다. 프로세스를 실행하려면 독자적인 메모리 공간과 CPU가 필요하다.
CPU는 한 번에 하나의 프로세스에만 할당할 수 있다. 여러 프로세스가 완벽하게 '동시에' 실행되는 건 불가능하다. 즉, 프로세스는 프로그램을 실행하는 순간부터 창을 닫을 때까지 계속해서 실행 상태로 있는 것이 아니다. 프로세스 상태는 상황에 따라 변한다.
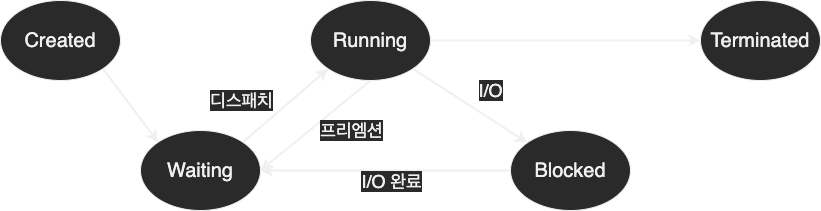
총 다섯 가지 상태가 있다.
1. 생성(Created) : 프로그램을 실행했을 때 프로세스가 생성되면서 실행 가능 상태가 된다. 곧바로 실행 상태가 되는 것이 아니라, 우선 실행 가능 상태가 되어 실행 중인 프로세스와 우선순위를 비교한 다음 우선순위가 높으면 실행되고 아니면 실행 가능 상태에서 순서를 기다리는 식이다.
2. 실행 가능(Waiting) : 실행 가능 상태의 프로세스는 언제든지 실행될 준비가 되어 있다. 운영체제는 인터럽트가 발생했을 때 실행 가능 상태의 프로세스 중 다음으로 CPU를 할당받아 살행될 프로세스를 결정한 후 실행 중인 프로세스와 교체한다. 이때 다음으로 실행될 프로세스에 CPU를 할당하는 것을 디스패치(displatch)라고 하고, 실행 중이던 프로세스에서 CPU를 해제하는 것을 프리엠션(preemption)이라고 한다.
3. 실행(Running) : 프로세스가 운영체제로부터 CPU를 할당받아 실행되고 있는 상태이다.
4. 보류(Blocked) : 프로세스가 I/O(입출력) 작업을 하면 CPU를 해제하고 보류 상태로 변경된다. 이때 실행 가능 상태의 프로세스 중 하나가 CPU를 할당받는다. 보류 상태에 들어간 프로세스는 I/O 작업이 모두 끝나면 실행 가능 상태로 변경된다. 중요한 점은 I/O 작업이 완료된 다음 바로 실행 상태로 변경되는 것이 아니라. 실행 가능 상태가 되어 실행되기를 기다린다는 점이다. 또한 실행 대기 상태(Waiting)와 보류(Blocked) 상태를 구분할 수 있어야 한다. 실행 대기 상태는 언제든지 다시 실행될 수 있는 상태를 말하지만 보류 상태는 I/O 작업이 끝나기 전에는 실행이 불가능한 상태이다.
5. 소멸(Terminated) : 프로세스 실행이 완료되어 메인 메모리에서 사라진다.
스케줄링
스케줄링(scheduling)이란 운영체제가 여러 프로세스의 CPU할당 순서를 결정하는 것이다. 이 일을 하는 프로그램을 스케줄러라고 한다.
스케줄링은 CPU를 언제 할당하는지에 따라 선점형 스케줄링(preemptive scheduling)과 비선점형 스케줄링(non-preemptive scheduling)으로 나눌 수 있다.
선점형 스케줄링에서는 어떤 프로세스가 실행 중에 있어도 스케줄러가 강제로 실행을 중지하고 다른 프로세스에 CPU를 할당할 수 있다. 이에 반에 비선점형 스케줄링에서는 실행 중인 프로세스가 종료되거나 I/O 작업에 들어가거나 명시적으로 CPU를 반환하기 전까지 계속해서 실행된다. 우선순위가 높은 프로세스가 생성되어도 실행 중인 프로세스가 자발적으로 CPU를 양보하기 전까지는 실행될 수 없다. 윈도우를 포함한 최근 운영체제는 멀티태스킹을 위해 선점형 스케줄링을 한다.
스케줄링 알고리즘의 종류는 매우 다양한데 그중 네 가지만 알아보자
- 우선순위(Priority) 알고리즘 : 프로세스에 우선순위를 매겨 우선순위가 높은 프로세스를 먼저 실행한다. 어떤 프로세스가 CPU를 할당받고 실행되는 도중에 우선순위가 높은 프로세스가 생성되면 스케줄러는 실행 중인 프로세스를 실행 가능 상태로 만들고 우선순위가 높은 프로세스를 실행한다. 계속해서 우선순위가 높은 프로세스가 생성되면 우선순위가 낮은 프로세스는 계속 CPU를 할당받지 못하는 현상이 발생하는데 이를 기아 상태(starvation)라고 한다. 이를 해결하기 위해 우선순위가 낮은 프로세스가 일정 시간 CPU를 할당받지 못하면 우선순위를 높여 실행될 수 있도록 만드는데 이러한 방법을 에이징(aging)이라고 한다.
- 라운드 로빈(Round-Robin) 알고리즘 : 실행 가능 상태에 있는 프로세스들을 순서대로 가져와 일정 시간 동안 CPU를 할당하는 방식이다. 모든 프로세스에 같은 시간이 부여된다. 이때 프로세스에 부여된 일정 시간을 타임 슬라이스(time slice) 혹은 퀀텀(quantum)이라고 한다. 라운드 로빈을 이용하면 모든 프로세스가 동시에 실행되는 것처럼 보인다. 대표적인 선점형 스케줄링이다. 라운드 로빈 스케줄링에서 가장 중요한 것은 타임 슬라이스를 얼마로 정하느냐이다. 너무 짧으면 컨텍스트 스위칭이 너무 자주 일어나 시스템에 부담이 되고 너무 길면 멀티태스킹을 구현하는 데 문제가 발생한다.
- FCFS(First Come First Served) : 실행 가능 상태에 먼저 들어온 프로세스를 먼저 실행하는 방법이다. 비선점 스케줄링이다.
- SJF(Shortest Job First) : 평균 대기 시간을 최소화하기 위해 CPU 할당 시간이 가장 짧은 프로세스를 먼저 실행한다. 우선순위 알고리즘처럼 할당 시간이 긴 프로세스는 계속해서 실행이 되지 않는 기아 상태에 빠질 수 있다. 또한 CPU의 실제 할당 시간을 알 수 없으므로 예측에 의존해야 하는 단점도 있다.
컨텍스트 스위칭
프로세스 두 개가 같은 프로그램에서 만들어졌을 때 두 프로세스는 어떤 차이가 있을까? 우선 두 프로세스는 독립된 메모리 공간을 가진다. 현재 실행 중인 인스트럭션이나 스택 프레임이 다를 것이다. 실행 중인 인스트럭션이 다르므로 프로그램 카운터 값도 다르고 스택 프레임도 다르니 스택 포인터와 프레임 포인터와 범용 레지스터의 값도 모두 다르겠다.
프로세스가 실행되려면 다양한 CPU 레지스터 값과 프로세스 상태 정보 등이 필요하다 .그러므로 프로세스가 실행 상태에서 실행 가능 상태로 변경될 때 이러한 정보를 메모리 어딘가에 저장해야 한다. 프로세스의 CPU 상태와 프로세스의 상태를 저장해 둔 메모리 블록을 프로세스 제어 블록(Process Control Block, PCB)이라고 한다.
PCB 데이터는 프로세스가 실행 가능 상태에서 실행 상태로 바뀔 때도 필요하다. 프로그램 카운터를 예를 들면 PCB에 저장된 프로그램 카운터 값을 CPU로 가져와야 이전에 실행한 마지막 인스트럭션의 다음 인스트럭션을 가져와 실행할 수 있다.
스케줄러가 실행 중인 프로세스에서 CPU를 해제하고 실행 가능 상태의 프로세스에 CPU를 할당할 때, 실행 중인 프로세스의 CPU 상태 정보를 그 프로세스의 PCB에 저장하고 곧 실행될 프로세스의 PCB에서 이전 CPU 상태 정보를 CPU로 가져오는 것을 컨테스트 스위칭(context switching)이라고 한다. CPU 상태를 컨텍스트라고 부르는데 말 그대로 현재 CPU의 레지스터 값들을 '전환(switching)'하는 것이다. 잦은 컨텍스트 스위칭은 시스템 성능을 떨어트린다.
스레드
스레드(thread)란 프로세스 안에 실행 흐름의 단위로 스케줄러에 의해 CPU를 할당받을 수 있는 인스트럭션의 나열이다. 프로세스는 하나 이상의 스레드로 구성된다.
프로세스가 PCB를 갖는 것처럼 스레드는 스레드 제어 블록(Thread Control Block, TCB)을 갖는다. TCB에는 스레드 ID, 각종 레지스터 정보, 스레드 상태 정보, 스레드가 속해 있는 프로세스의 PCB 주소 등이 저장되어 있다. TCB 정보는 PCB와 매우 유사하다. CPU의 레지스터 정보와 스레드의 상태 정보는 정확하게 프로세스와 같다. 즉, 프로세스 상태나 컨텍스트 스위칭이 스레드에도 똑같이 적용된다.
프로세스와 스레드 모두 인스트럭션의 나열이고 유사한 정보가 든 메모리 블록을 갖는다. 프로세스가 단일 스레드로 작동하면 프로세스와 스레드는 차이가 없다. 프로세스와 스레드의 차이점을 알려면 멀티프로세스와 멀티스레드를 비교해야 한다.
멀티프로세스(multi-process)는 프로세스 여러 개를 동시에 실행하는 것을 말하고, 멀티스레드(multi-thread)는 스레드를 여러 개 만들어 동시에 실행하는 것을 말한다.
멀티프로세스와 멀티스레드
단일 코어 CPU에서 여러 개의 실행 흐름이 동시에 필요하다고 가정해 보자. 예를 들어 대용량 데이터를 분석하는 프로그램을 만들고 있다고 가정해 보자.
필요한 모든 데이터를 네트워크에서 전송받아 사용자의 명령을 실행하면 아마도 사용자는 프로그램이 멈췄다고 생각할 것이다. 이 때 UI를 담당하는 실행 흐름에서는 사용자가 현재까지 읽어 들인 데이터를 가지고 분석 및 시각화할 수 있도록 명령을 받는다. 프로그램 화면에는 모든 데이터를 받았는지를 표시등을 이요해 시각적으로 보여 준다.
다른 실행 흐름에서는 메모리의 힙 영역을 충분히 확보해 놓은 뒤 네트워크에서 데이터를 계속 수신해 저장한다. 나머지 하나의 실행 흐름에서는 지금까지 받은 데이터를 이용해 사용자의 명령을 수행한다.
UI 담당 실행 흐름과 네트워크 수신 실행 흐름에서는 데이터 수신 완료 여부를 나타내는 데이터를 서로 공유해야 한다. 왜냐하면 네트워크 수신 실행 흐름에서 데이터 수신을 완료했을 때 UI 담당 실행 흐름에서는 프로그램 화면의 데이터 수신 완료 표시등에 표시를 해야 하기 때문이다.
또한 네트워크 수신 실행 흐름과 데이터 분석 실행 흐름에서는 지금까지 받은 데이터(메모리의 힙 영역에 저장된 데이터)를 공유해야 한다. 그래야 데이터를 이용해 사용자의 명령을 즉각적으로 수행할 수 있기 때문이다.
이처럼 실행 흐름 사이에서 데이터를 공유해야 하는 경우는 흔하다. 실행 흐름 하나가 데이터를 변경했을 때 다른 흐름도 변경된 데이터를 업데이트할 수 있어야 한다. 실행 흐름은 결국 CPU를 점유하고 인스트럭션을 실행하는 것을 말하므로 여러 실행 흐름을 구현하려면 멀티프로세스나 멀티스레드로 구현해야 한다.
먼저 멀티프로세스로 구현한다고 가정해 보자. 프로세스는 서로 독립적인 메모리 공간을 가지므로 기본적으로 데이터를 공유할 수 없다.

위의 그림을 보면 멀티프로세스에서는 모든 프로세스가 서로 다른 메모리 공간을 가지므로 데이터를 공유라려면 특별한 기법을 사용해야 한다.
하지만 멀티스레드로 구현하면 데이터를 쉽게 공유할 수 있다. 멀티프로세스와 달리 여러 스레드가 스택만 서로 다른 공간을 갖고 코드, 데이터, 힙은 공유하기 때문이다.
다음은 프로세스 안에 있는 멀티스레드의 메모리 구조이다.

스레드는 각자 독립적인 스택 세그먼트를 갖지만, 코드, 데이터, 힙은 다른 스레드와 공유한다. 데이터 세그먼트나 힙 세그먼트에 공유 데이터를 두면 모든 스레드가 이용할 수 있다.
메모리 구조만 봐도 실행 흐름이 동시에 필요하고 더욱이 공유 데이터가 있다면 멀티스레드로 구현하는 것이 훨씬 합리적일 것이다. 이처럼 동시에 여러 실행 흐름이 필요한 프로그램을 동시성(concurrency) 프로그래밍이라고 하고 이를 구현하고자 멀티스레딩을 이용한다.
멀티스레딩 구현
0~1000까지의 정수가 담긴 리스트에서 모든 요소의 값을 두 배로 만들려고한다. 다음은 단일 스레드로 실행하는 코드이다.
li = [i for i in range(1001)]
for idx in range(1001):
li[idx] *= 2똑같은 작업을 실행 흐름 네 개로 나누어 처리해 보자.
import threading
# 리스트 요소 개수
num_ele = 1000
# 스레드 개수
num_thread = 4
offset = num_ele // num_thread
li = [i+1 for i in range(num_ele)]
def thread_main(li: list, i: int):
for i in range(offset * i, offset * (i + 1)):
li[i] *= 2
threads = []
for i in range(num_thread):
th = threading.Thread(target=thread_main, args=(li, i))
threads.append(th)
for th in threads:
th.start()
for th in threads:
th.join()
print(li)
""" 결과
[2, 4, 6, 8, 10, 12, ...]
"""요소 개수가 1000개라면 스레드가 네 개이므로 스레드 하나당 250개 요소를 맡아 연산한다. 모든 스레드가 같은 리스트를 인자로 받되 정수 i가 0~3 스레드마다 다르다.
Thread객체 th를 생성한다. target은 스레드에서 실행할 함수고 args는 함수에 전달할 인자이다.
start() 메서드는 스레드를 시작하는 메서드, join 메서드는 스레드 실행이 종료될 때까지 기다리는 메서드이다.
타임 슬라이스
스레드는 일정한 시간 간격으로 CPU를 할당받아 연산하는데, 이때 일정한 시간 간격을 타임 슬라이스라고 한다. 파이썬의 sys 모듈을 사용하면 타임 슬라이스를 알 수 있다.
import sys
sys.getswitchinterval()
""" 결과
0.005
"""sys 모듈의 getswitchinterval() 메서드는 파이썬의 멀티스레딩에서 각 스레드의 실행 시간인 타임 슬레이스를 보여준다.
경쟁 조건
import threading
# 모든 스레드가 공유할 데이터
g_count = 0
# thread가 실행할 함수
def thread_main():
global g_count
for i in range(100000):
g_count += 1
threads = []
for i in range(50):
th = threading.Thread(target=thread_main)
threads.append(th)
for th in threads:
th.start()
for th in threads:
th.join()
print('g_count: {:,}'.format(g_count))
""" 결과
g_count: 4,116,610
# 실행할 때마다 달라짐...
g_count: 4,589,055
"""전역 변수 g_count를 선언하고 thread_main() 함수 안에서 g_count 값에 1을 100,000번 더한다.
for문으로 스레드를 총 50개를 만들었으니 스레드 50개가 동시에 g_count에 접근하여 값을 수정하려고 시도할 것이다. 이처럼 여러 스레드가 동시에 접근, 수정, 공유 가능한 자원을 '공유 자원'이라고 한다. 위의 예제에서는 g_count라는 전역 변수가 공유 자원이다.
g_count의 최종 값은 스레드 50개가 각각 100,000번씩 값을 증가시키므로 5,000,000이 될 것 같았다. 하지만 실행 결과를 보면 매번 다른 값이 나온다. 왜일까?
컨텍스트 스위칭이 언제 일어나는지에 따라 전혀 다른 결과가 나오는 것이다. 이처럼 스레드 여러 개가 공유 자원에 동시에 접근하는 것을 '경쟁 조건(race condition)'이라고 한다.
보통 경쟁 조건은 심각한 문제를 일으킨다. 위의 예제처럼 여러 스레드가 g_count에 단순히 접근만하고 값을 변경하지 않으면 아무런 문제도 발생하지 않는다. 하지만 스레드안에 있는 코드가 g_count 값에 1을 더하려고 하면 문제가 발생한다. 이처럼 공유 자원에 접근해 변경을 시도하는 코드를 임계 영역(critical section)이라고 한다.
상호 배제
경쟁 조건 문제를 해결하기 위해서 상호 배제(mutual exclusion)를 사용한다. 상호 배제의 원리는 매우 간단하다. 스레드 하나가 공유 자원을 이용하는 동안에는 다른 스레드가 접근하지 못하게 막는 것이다.
파이썬에서는 주로 Lock 객체를 활용한다.
import threading
# 모든 스레드가 공유할 데이터
g_count = 0
# lock 객체 생성
lock = threading.Lock()
# thread가 실행할 함수
def thread_main():
global g_count
# lock 획득.
lock.acquire()
for i in range(100000):
g_count += 1
lock.release()
threads = []
for i in range(50):
th = threading.Thread(target=thread_main)
threads.append(th)
for th in threads:
th.start()
for th in threads:
th.join()
print('g_count: {:,}'.format(g_count))
""" 결과
g_count: 5,000,000
"""먼저 Lock 객체를 생성하고 임계 영역이 시작되는 곳에서 lock의 acquire() 메서드를 호출한다.
acquire() 메서드는 Lock 객체를 '획득'한다. 한 스레드가 획득한 다음에는 다른 스레드가 acquire() 메소드를 호출해도 다른 스레드는 Lock 객체를 획득하지 못하고 대기 상태에 있다. Lock 객체를 획득했던 스레드가 임계 영역을 빠져나와 release() 메소드를 호출한다. release() 메서드는 Lock 객체를 '반환' 한다.
임계 영역을 빠져나온 스레드가 Lock 객체를 반환할 때 여러 스레드가 acquire() 메서드 호출로 인해 대기 상태에 있다면 그중 한 스레드가 Lock 객체를 획득하고 임계 영역에 진입한다.
실행 결과를 보면 예상한 값이 정확히 나오는 것을 볼 수 있다.